Monocular depth estimation is a critical task in computer vision, and self-supervised deep learning methods have achieved remarkable results in recent years. However, these models often struggle on camera generalization, i.e. at sequences captured by unseen cameras. To address this challenge, we present a new public custom dataset created using the CARLA simulator, consisting of three video sequences recorded by five different cameras with varying focal distances. This dataset has been created due to the absence of public datasets containing identical sequences captured by different cameras. Additionally, it is proposed in this paper the use of adversarial training to improve the models’ robustness to intrinsic camera parameter changes, enabling accurate depth estimation regardless of the recording camera. The results of our proposed architecture are compared with a baseline model, hence being evaluated the effectiveness of adversarial training and demonstrating its potential benefits both on our synthetic dataset and on the KITTI benchmark as the reference dataset to evaluate depth estimation.
Generated dataset: http://www-vpu.eps.uam.es/publications/UnSyn-MF Dataset/ .
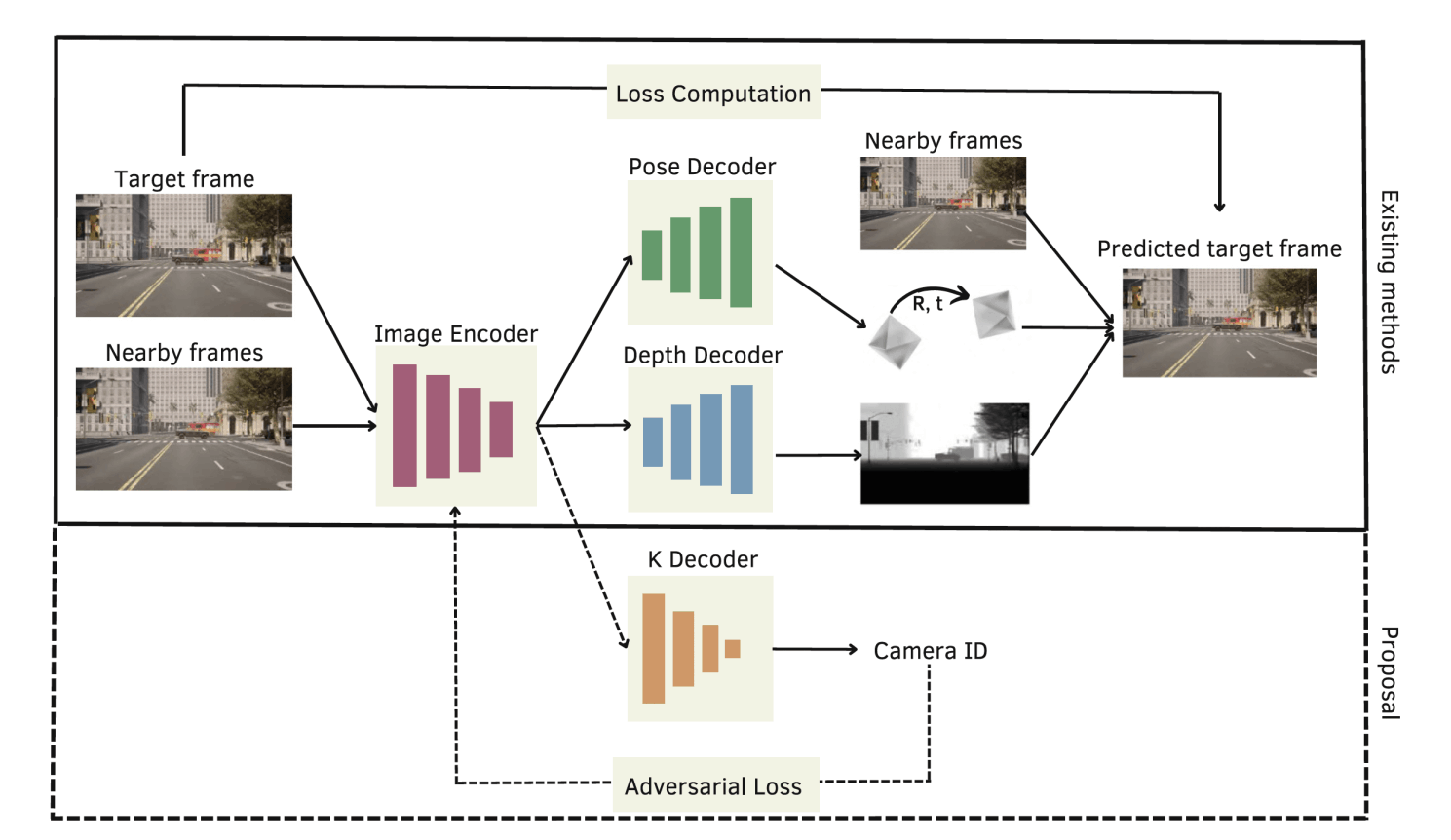
Overview of self-supervised monocular depth estimation and the inclusion of adversarial training as our proposal. First, feature extraction is performed for a target frame and nearby ones (Image Encoder). Second, the pose change between each pair of consecutive frames is obtained (Pose Decoder), as well as the depth map of the target frame (Depth Decoder). Then, a reconstruction of the target frame is generated and used as the supervisory signal. Proposal: adding a classifier for the camera (K Decoder) in an adversarial manner to achieve features invariant to camera changes.
New synthetic dataset.
Created a public dataset with identical sequences captured by multiple cameras with different focal lengths to fairly evaluate camera generalization.
Adversarial training approach.
Introduced a camera-classifier branch trained adversarially to make feature representations invariant to camera intrinsics.
Improved generalization.
Demonstrated that the proposed method outperforms baselines on both the custom dataset and the KITTI benchmark, especially on unseen cameras.
Reference:
@inproceedings{diana2023self,
title={Self-supervised monocular depth estimation on unseen synthetic cameras},
author={Diana-Albelda, Cecilia and Bravo P{\'e}rez-Villar, Juan Ignacio and Montalvo, Javier and Garc{\'\i}a-Mart{\'\i}n, {\'A}lvaro and Besc{\'o}s Cano, Jes{\'u}s},
booktitle={Iberoamerican Congress on Pattern Recognition},
pages={449--463},
year={2023},
organization={Springer}
}

No Code Website Builder